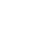



[Python][Scrapy][爬虫]爬虫应用实战–重大新闻网新闻摘要
因为工作需要,使用爬虫来完成一些统计工作,主要需要获取的内容为文章的字数、阅读量等。
创建Scrapy项目
-
新建Scrapy项目
scrapy startproject cqu_news -
新建一个Crawl爬虫模板
scrapy genspider crawl news.cqu.edu.cn -
Item数据模型
打开cqu_news文件夹下的items.py,新建一个CquNewsItemclass
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class CquNewsItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
time = scrapy.Field()
title = scrapy.Field()
abstract = scrapy.Field()
link = scrapy.Field()
cover = scrapy.Field()
source = scrapy.Field()
page = scrapy.Field()
# content = scrapy.Field()
- 爬虫模板长这个样~
页面数据获取逻辑分析
下一步就是找找页面中有哪些需要获得的信息,可以使用bs4来处理,不过bs包比较大,可能影响执行效率。这里还是建议使用scrapy自带的选择器response.css()和response.xpath()来获取,使用时候相应的API也是非常完善的。
处理新闻首页
这里以这条http://news.cqu.edu.cn/newsv2/news-126.html为例,可以看到顶部是常驻新闻,而底部才是我们感兴趣的新闻的摘要。提取:
更正:这里实际使用的是这条物理学院王锐发表关于“磁性氧化中拓扑量子态”的 前瞻性(Perspective)邀请综述 - 新闻 - 重庆大学新闻网
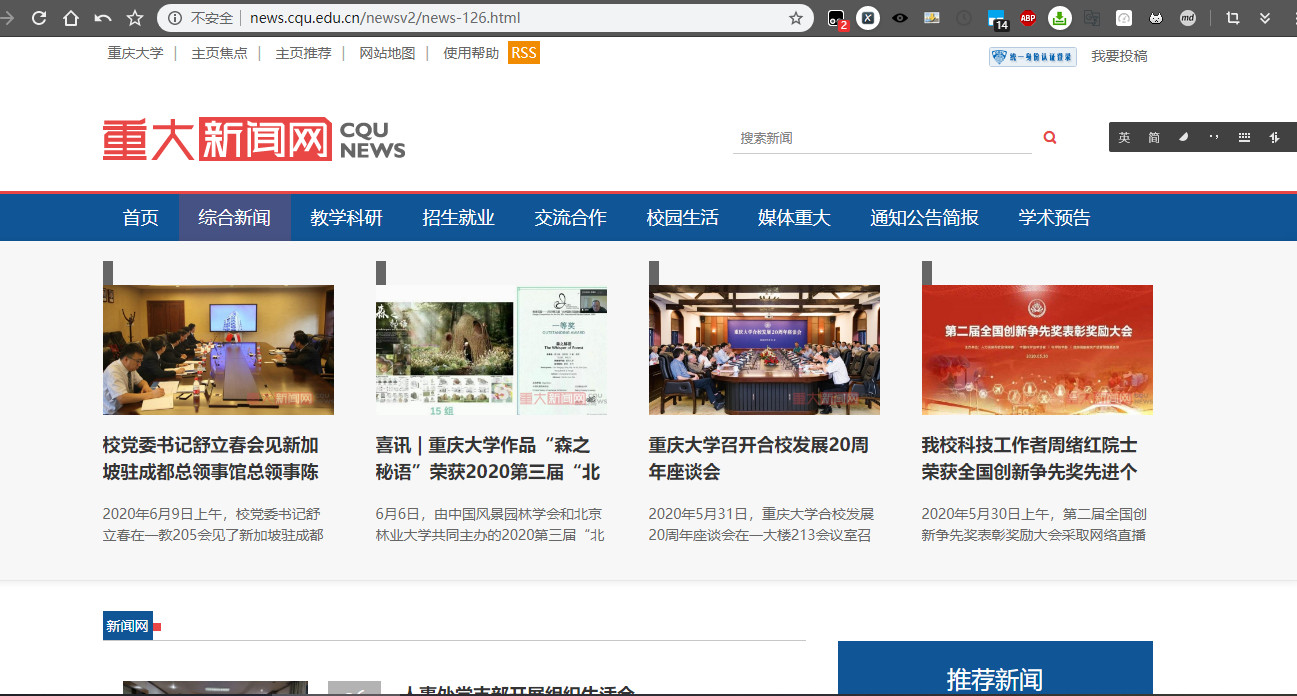
这里主要是获取新闻页面,同时抓取新闻的时间,摘要、链接和头图(可能没有头图)。

在正式开始爬之前,我们应该首先注意到了位于页面底部的跳转链接,这里有一个非常重要的信息就是新闻网总共的页码数,方便生成系列链接,顺序爬取。
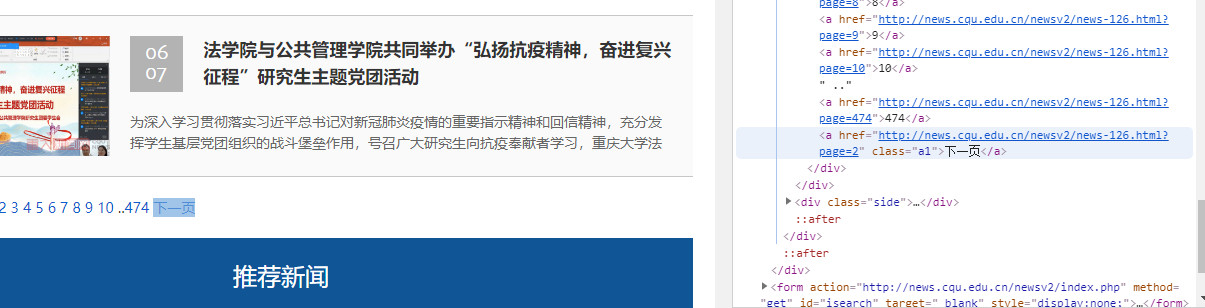
这里我们发现,跳转页面都是使用query方式传递耽搁页面参数?page=xxx进行的一次查询,处理单页跳转并无难度,所以这里我们只需要提取到总页数即可。
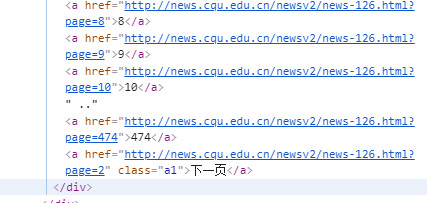
这是一个位于div[@page]下方的普通<a/>链接,所以这里只需要取相对位置即可,即先找到相对有特点的下一页元素,再回溯一个兄弟元素即可。代码如下:
class CrawlSpider(scrapy.Spider):
name = 'crawl'
allowed_domains = ['news.cqu.edu.cn']
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36"
}
start_urls = ['http://news.cqu.edu.cn/newsv2/news-126.html']
def parse(self, response):
url = response.url
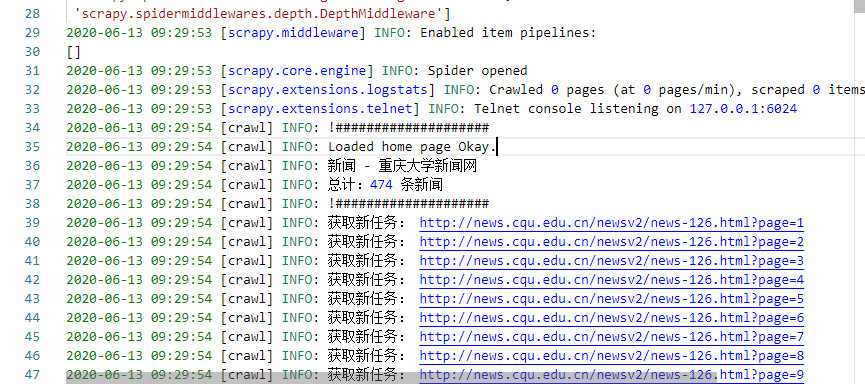
self.log("当前地址:" + response.url)
if(response.status == 200):
self.log("!" + "#"*20, level=logging.info)
self.log("Loaded home page Okay.", level=logging.info)
bs = BeautifulSoup(response.body, features="lxml")
# 页面标题
self.log(bs.find("title").text, level=logging.info)
# 获取“下一页”div标签
nextpage = bs.find("a", attrs={"class": "a1"}, text="下一页")
# 获取总页码数
pages = int(nextpage.find_previous_sibling().text)
self.log("总计:" + str(pages) + " 条新闻", level=logging.info)
self.log("!" + "#"*20, level=logging.info)
处理新闻页
其实简单的统计只需要上面的列表就够了,也可以节约大量时间和网络资源,不过其中的作者、新闻日期还有阅读量数据,只有点进页面内才能看得到,也是一大坑点。因为必须要用到,所以这里就把正文连同一起也采集下来算惹~
启动一个Scrapy shell方便调试

新闻页面顶部:标题、作者、日期、摘要
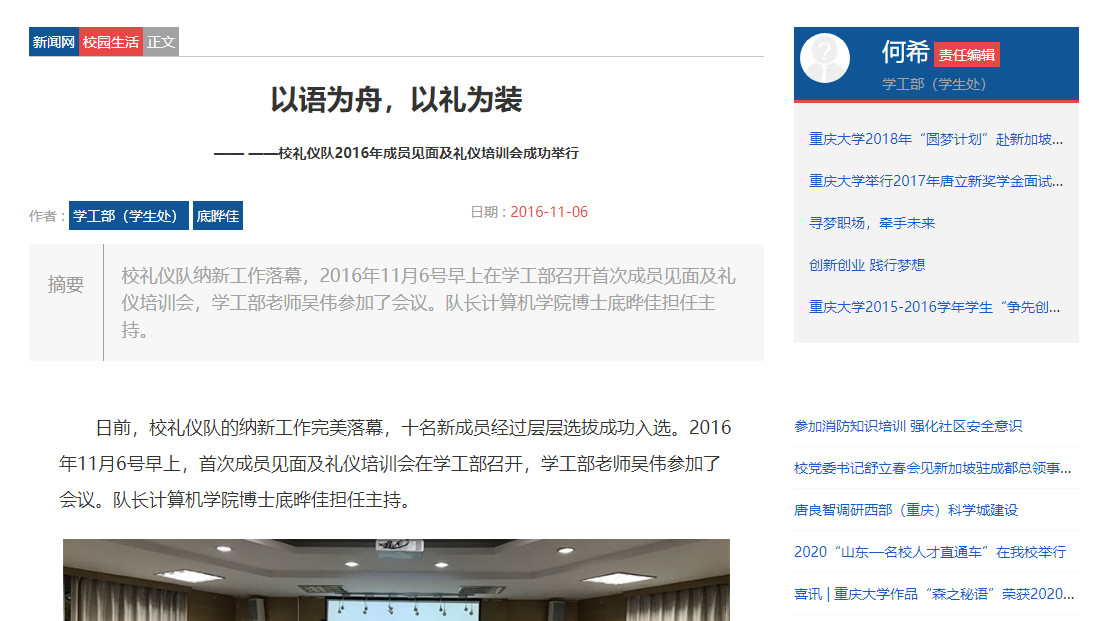
首页顶部需要关注的内容有:标题、作者、日期、摘要,以及右侧的编辑信息。

提取标题:
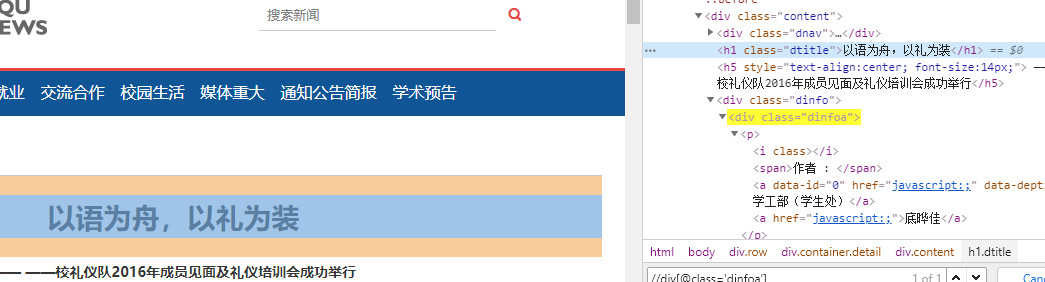
这里测试了,只需要使用一个简单的匹配语句即可:

为了严谨和提高稳定性,还是加上一些限制条件。
response.xpath("//h1[@class='dtitle']/text()").get()
提取作者信息:
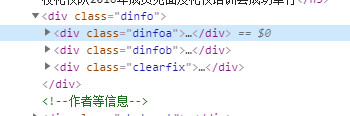
作者和日期信息集中在这个dinfo类的div当中,可以很方便的提取到。
", ".join(response.xpath("//div[@class='dinfoa']/p//*/text()").getall())

提取日期信息:
同理可以提取到日期信息,在div[@class=‘dinfob’]当中:
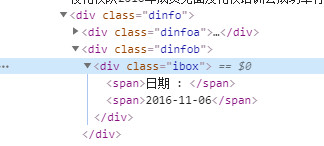
这里用类似的方法提取即可。
" ".join(response.xpath("//div[@class='dinfob']/div//*/text()").getall())

或者也可以使用:response.xpath("//div[@class='ibox']/span[2]/text()").get()
获得的效果:
摘要提取:
摘要提取很简单,只集中在一个div[@adetail]的标签中,获取得到:

可以看到其原文就有很多的空行,用于排版对齐,所以这里需要进一步除去多余空行,所以加一个正则去空格处理。
代码:
data['content'] = re.sub('\s', '', response.xpath("//div[@class='adetail']/text()").get())
最终效果

正文提取
这里正文结构也很简单:
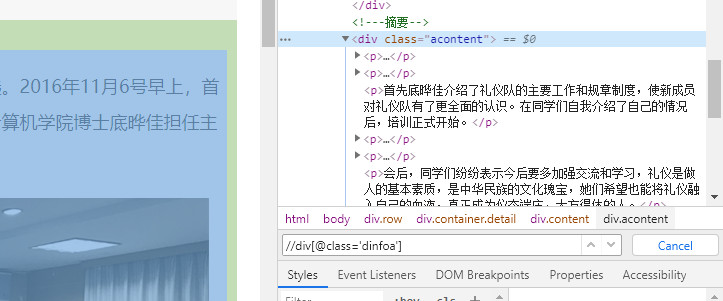
直接上代码:
"\r\n".join(response.xpath("//div[@class='acontent']//p/text()").getall())
提取效果:

尾部标签、阅读量提取

在新闻尾部有阅读量、标签信息,尤其标签在前面的首页摘要当中是没有体现的,必须到内部来获取。
新闻标签提取:
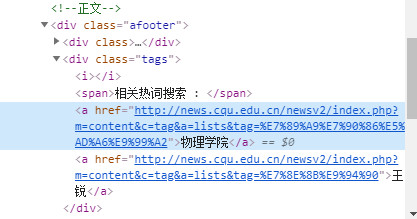
标签同样的结构简单:
data['tags'] = ', '.join(response.xpath("//div[@class='tags']/a/text()").getall())
结果:

新闻阅读量提取:
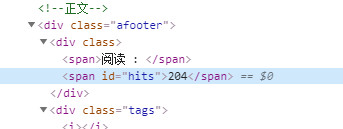
直接体现在div[@class='hits']中,故代码:

运行后发现不对劲,这个hits始终获取到的都是0,查看源代码:
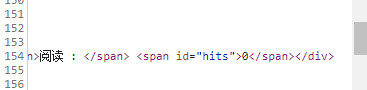
原始网页中就直接是0, 同时刷新网页可以看到其点击量也在增加,所以不是伪造或者静态的数据。首先判断应该是有数据库和js脚本通过xhr得到点击量,所以再尝试一下拦截带有hits关键词的XHR。
无果…
最后,直接trigger这个元素的修改断点,发现在js代码中修改了点击量:
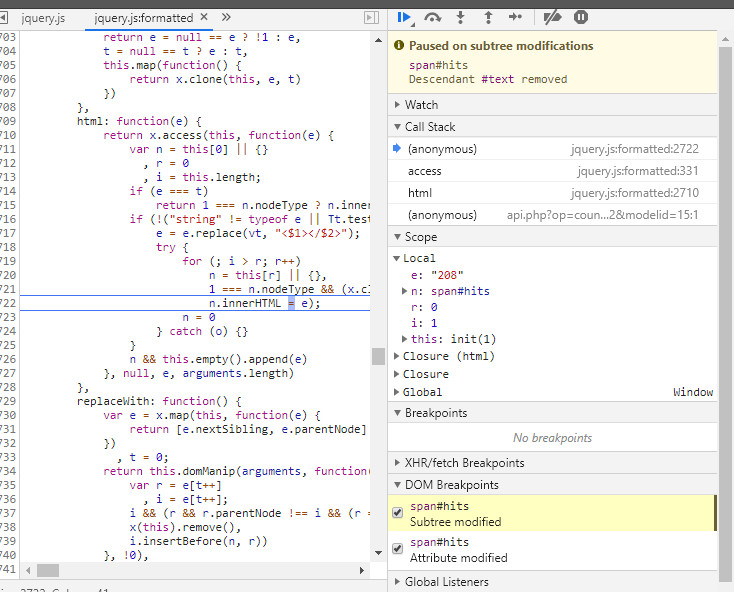
断点原因是:
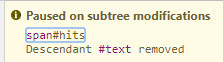
也即使原本的零被修改为实际访问量,那么这个访问量又是怎么获取到的呢?
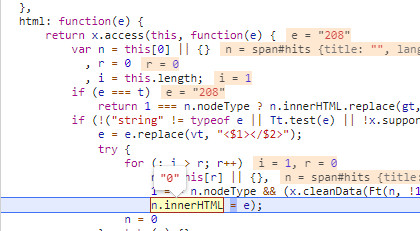
在这个断点内可以看到,e的值是208,恰好是实际访问量,也是这个叫做html(这里吐槽一下混乱随意的函数命名)的函数传入参数也是e=208。而被替换的n.innerHTML值也恰好等于"0",只需要溯源208是哪里来的就可以了。通过程序调用栈可以看到,上级调用为:
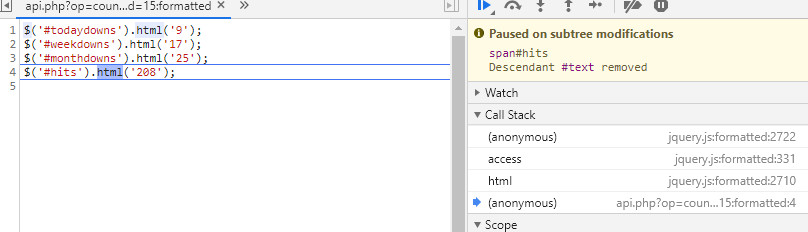
是一个匿名的函数调用,来源于一个webapi,那么这个也就是我们最终要获取点击量的来源了:

这里的id也就是网页中的倒数第二个连字符节,直接获取并查询即可。

通过请求得到的结果也符合预期:

最终的爬虫代码
# -*- coding: utf-8 -*-
import scrapy
import os
import re
import logging
from bs4 import BeautifulSoup
from scrapy import Request
from cqu_news.items import CquNewsItem
class CrawlSpider(scrapy.Spider):
name = 'crawl'
allowed_domains = ['news.cqu.edu.cn']
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36"
}
start_urls = ['http://news.cqu.edu.cn/newsv2/news-126.html']
def parse(self, response):
url = response.url
self.log("当前地址:" + response.url)
if(response.status == 200):
self.log("!" + "#"*20, level=logging.info)
self.log("Loaded home page Okay.", level=logging.info)
bs = BeautifulSoup(response.body, features="lxml")
self.log(bs.find("title").text, level=logging.info)
nextpage = bs.find("a", attrs={"class": "a1"}, text="下一页")
pages = int(nextpage.find_previous_sibling().text)
self.log("总计:" + str(pages) + " 条新闻", level=logging.info)
self.log("!" + "#"*20, level=logging.info)
for i in range(1, pages+1):
#for i in range(2, 5):
url0 = url + "?page="+str(i)
self.log("获取新任务: " + url0, level=logging.info)
yield Request(url0, callback=self.parse_page, errback=self.onerror, headers=self.headers, cb_kwargs={"src": url0})
def parse_page(self, response, src):
self.log("!" + "#"*10 + " 获取页面 #" +
str(re.search("[\d]+$", response.url)[0]) + "#"*10, level=logging.info)
self.log(response.url)
bs = BeautifulSoup(response.body, features="lxml")
title = bs.find("title").text
self.log("标题:" + title)
items = bs.findAll("div", attrs={"class": "item"})
for it in items:
data = CquNewsItem()
data['title'] = re.sub("\s", "", it.find('div', attrs={"class": "title"}).text)
data['time'] = re.sub("\s", "", it.find('div', attrs={"class": "rdate"}).text)
postimg = it.find('img')
if postimg is not None:
cover = postimg.attrs['src']
data['cover'] = "http://news.cqu.edu.cn" + it.find('img').attrs['src']
data['abstract'] = re.sub("\s", "", it.find('div', attrs={"class": "abstract"}).text)
data['link'] = it.find('a').attrs['href']
data['source'] = str(src)
data['page'] = re.search("[\d]+$", str(src)[0])
self.log("!" + "#"*10 + " 页面结束 #" +
str(re.search("[\d]+$", response.url)[0]) + "#"*10)
yield Request(data['link'], callback=parse_news, cb_kwargs={"data": data})
# yield data
def parse_news(self, response, data):
data["data"] = response.xpath("//div[@class='ibox']/span[2]/text()").get()
data['content'] = response.xpath("//div[@class='acontent']//p/text()").getall().join("\n")
self.log("@标签:" + " @阅读量:", level=logging.info)
yield data
食用方法

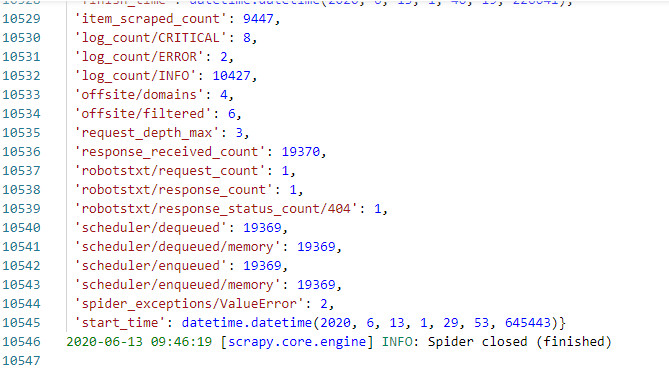
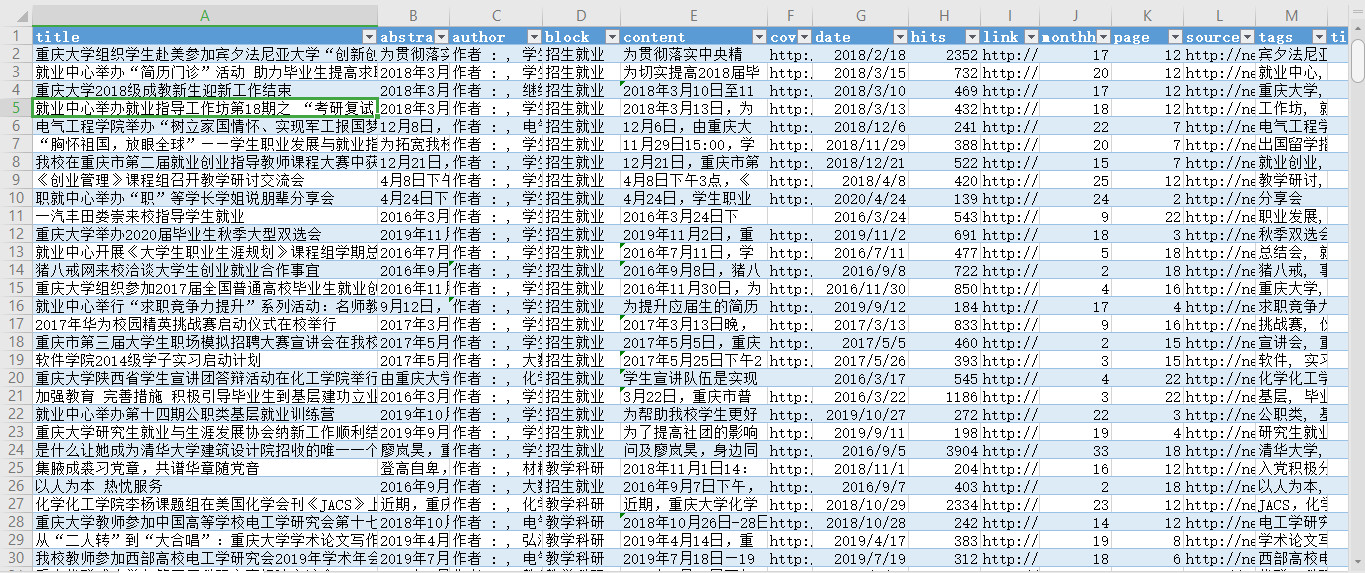
运行效果图: