






【Python】Python正则表达式re.sub()之原位替换
首先讲一下背景,这里是一个API网页接口,其中的html内容为了便于使用json进行传输,使用了许多escape 格式,类似 \x22 \x3C 的样子,这里贴一部分:
>>> feed = r'class=\x22info-detail\x22>\x3Cspan class=\x22 ui-mr8 state\x22 >3月7日 22:01\x3C\/span>\x3Ca href=\x22javascript:;\x22 data-cmd=\x22qz_sign\x22 class=\x22f-sign-show state\x22 title=\x22我也要设置\x22>\x3C\/a>\x3C\/div>\x3C\/div>\x3C\/div>\x3Cdiv class=\x22f-single-content f-wrap\x22>\x3Cdiv class=\x22f-item f-s-i\x22 id=\x22feed_....._311_0_1583589681_0_1\x22 data-feedsflag=\x22\x22 data-iswupfeed=\x221\x22 data-key=\x227e6e330318a9635e0a8f0000\x22 data-specialtype=\x22\x22 data-extend-info=\x220_0_1_0_0_0_0|08009cc0040f5001|0008000000000000\x22 data-functype=\x22\x22 data-hasfollowed=\x221\x22>\x3Cdiv class=\x22f-info qz_info_cut\x22>我教你们怎么做舔狗,一天三遍请安记得把称呼带上,哥哥早上好,哥哥晚上好,对方回你一句话赶紧十句话顶上去嘘寒问暖要安排上,吃了吗?在干嘛?下雪了吗?下雨了吗?冷吗?加衣服了吗?哥哥你那里降温了记得添衣服,哥哥你那里下雨了记得带伞,哥哥你在哪?哥哥我请你吃饭,哥哥晚上有时间吗?哥哥中午有时间吗?哥哥辛苦了,哥哥穿这身真帅,哥哥你看今晚的星星,哥哥你要睡觉了吗?哥哥我觉得这个特别适合你就给你买了你别不高 \x3Ca'
经过一反度娘科普,发现其实也就是对html标签tag中的< > ' ' 进行了转义,但又不一定只有这几种情况,总的来讲,这些符号全都属于 ascii 编码的范畴,所以我们要做的就是对这些转义字符进行逆向解码。
首先呢,二狗在这里尽量尝试不借助Python文档以外的外界超自然力量进行研究,首先想到这个可否使用 Python 自带的编解码函数进行解码呢?毕竟 Python3 对自然语言编码可是增强了一大截,这点小问题应该难不倒万能胶语言的嘛?
我们的基本思路是:
- 方案一:首先看是否存在
str类的二次解码函数。 - 方案二:其次就是曲线救国路线,线进行一次额外的编码,而后再进行一次解码。
那么问题来了,怎样进行编解码呢?我首先想到的是 str 类的 str.encode() 函数,以及其对应的解码函数 byte.decode() ,这两个函数的功能分别是:
-
str.encode(encoding="utf-8", errors="strict")对文本字符串进行编码,接收一个编码类型参数,编码结果为一个byte型的编码数据。 -
byte.decode()用于对 字节型 数据进行解码,解码结果为一个str字符串,可以传递一个编码参数,也可以不提供,这时函数库会自动根据编码特性进行 猜测 ,这当然本身是一个复杂的工作,不过我们用的是python,强大的函数库的确为我们大幅度减少了工作量。
那么又问题来了,Python到底支持那些编码格式,我们又该用哪种方案进行解码呢?
这里贴出Python的两处文档,一个是str.encode()函数,一个是codecs 专栏,也就是专门讲解python中编解码的详尽列表。
我们可以看到这里一个非常权威且霸道的用词:
标准编码
Python 自带了许多内置的编解码器,它们的实现或者是通过 C 函数,或者是通过映射表。 以下表格是按名称排序的编解码器列表,并提供了一些常见别名以及编码格式通常针对的语言。 别名和语言列表都不是详尽无遗的。 请注意仅有大小写区别或使用连字符替代下划线的拼写形式也都是有效的别名;因此,‘utf-8’ 是 ‘utf_8’ 编解码器的有效别名。
这个表格大体是这个格式:
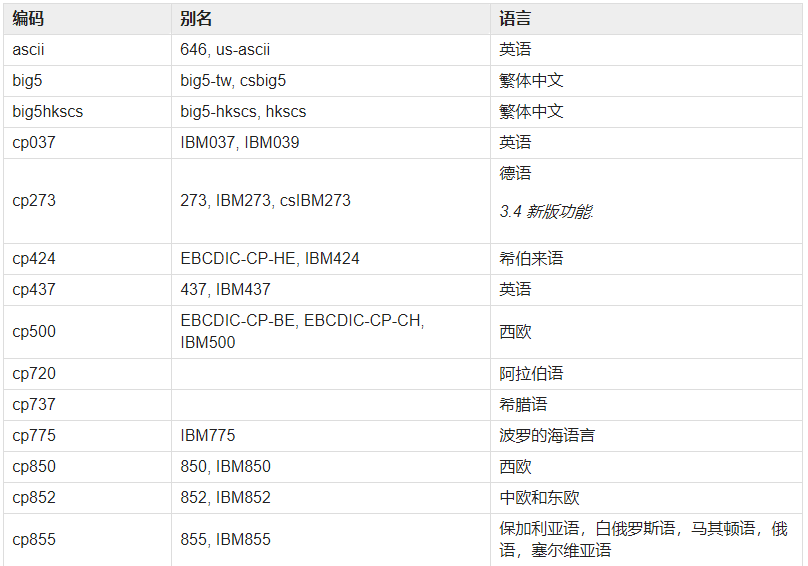
我们搜索ASCII关键字,发现其中涉及到ASCII的寥寥无几,反正是为了偷懒,司马当活马医,看上哪个就用哪个了。
首先是方案一
这里,通过python文档并没有看到这种奇奇怪怪的解码函数,因为的确有些小众了,这里实在有些按耐不住,还是动用了外部力量,发现的确曾经有前辈研究过这类问题:
参考链接:
没错,结果呢,我们发现这两个都使用了一个非常神奇的操作,一下子就得到了解码后的结果:都是用了一个str.decode('string-escape') 称之为“文本转义”的解码方式,然鹅,我们用的是Py3,其中已经找不到这个函数了。
>>> feed.decode('string-escape')
Traceback (most recent call last):
File "<pyshell#287>", line 1, in <module>
feed.decode('string-escape')
AttributeError: 'str' object has no attribute 'decode'
>>>
要相信天无绝人之路,我们继续搜搜,发现了这个stackoverflow的贴子,其中介绍的是关于python3 中的实现方法。
3. how do I .decode(‘string-escape’) in Python3?
问法非常直接粗暴,果然是老外的办事风格,严谨认真且直捣黄龙。
I have some escaped strings that need to be unescaped. I’d like to do this in Python.
For example, in python2.7 I can do this:
>>> "\\123omething special".decode('string-escape')
'Something special'
>>>
How do I do it in Python3? This doesn't work:
>>> b"\\123omething special".decode('string-escape')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
LookupError: unknown encoding: string-escape
>>>
My goal is to be abel to take a string like this:
s\000u\000p\000p\000o\000r\000t\000@\000p\000s\000i\000l\000o\000c\000.\000c\000o\000m\000
And turn it into:
"support@psiloc.com"
After I do the conversion, I’ll probe to see if the string I have is encoded in UTF-8 or UTF-16.
我们看到了几个提供了线索的答案,也就是:
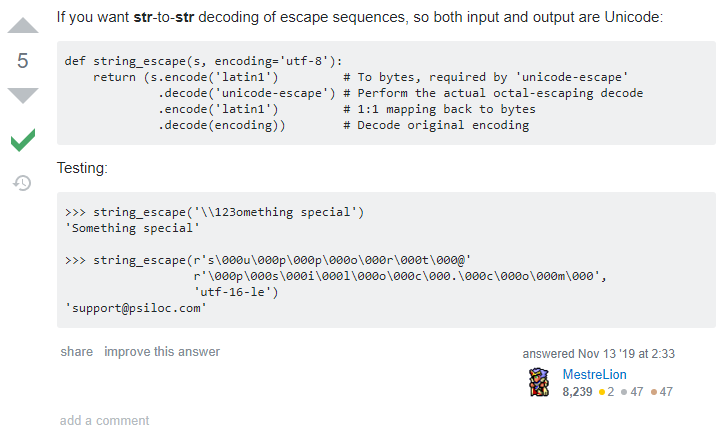
这里是使用了编码后解码的方案,这里我也找到了另外一个看起来比较靠谱的代码:
feed.encode('utf8').decode('unicode_escape')
这个代码也就是首先对 str 进行utf8编码,而后作为unicode的escape文本进行解码,完成解码操作,我们实际操作一番:
>>> ss = r'\x23\x45\x3C'
>>> ss.encode('utf8').decode('unicode_escape')
'#E<'
>>>
似乎效果立杆见影!看来这里在进行utf8编码时,并没有将转义符号进行二次编码,而后一次解码则刚刚好将utf8编码时的新转义字符连同原有的转义字符一起进行了解码,实现最终解码的效果,管它具体原理呢,把代码超过来试一把…果然,抄代码一时爽,一直抄…结果终于就出事故了:
>>> feed.encode('utf8').decode('unicode_escape')
'class="info-detail"><span class=" ui-mr8 state" >3æ\x9c\x887æ\x97¥ 22:01<\\/span><a href="javascript:;" data-cmd="qz_sign" class="f-sign-show state" title="æ\x88\x91ä¹\x9fè¦\x81设置"><\\/a><\\/div><\\/div><\\/div><div class="f-single-content f-wrap"><div class="f-item f-s-i" id="feed_53702270_311_0_1583589681_0_1" data-feedsflag="" data-iswupfeed="1" data-key="7e6e330318a9635e0a8f0000" data-specialtype="" data-extend-info="0_0_1_0_0_0_0|08009cc0040f5001|0008000000000000" data-functype="" data-hasfollowed="1"><div class="f-info qz_info_cut">æ\x88\x91æ\x95\x99ä½\xa0们æ\x80\x8eä¹\x88å\x81\x9aè\x88\x94ç\x8b\x97ï¼\x8cä¸\x80天ä¸\x89é\x81\x8d请å®\x89è®°å¾\x97æ\x8a\x8a称å\x91¼å¸¦ä¸\x8aï¼\x8cå\x93¥å\x93¥æ\x97©ä¸\x8a好ï¼\x8cå\x93¥å\x93¥æ\x99\x9aä¸\x8a好ï¼\x8c对æ\x96¹å\x9b\x9eä½\xa0ä¸\x80å\x8f¥è¯\x9d赶紧å\x8d\x81å\x8f¥è¯\x9d顶ä¸\x8aå\x8e»å\x98\x98å¯\x92é\x97®æ\x9a\x96è¦\x81å®\x89æ\x8e\x92ä¸\x8aï¼\x8cå\x90\x83äº\x86å\x90\x97ï¼\x9få\x9c¨å¹²å\x98\x9bï¼\x9fä¸\x8bé\x9bªäº\x86å\x90\x97ï¼\x9fä¸\x8bé\x9b¨äº\x86å\x90\x97ï¼\x9få\x86·å\x90\x97ï¼\x9få\x8a\xa0è¡£æ\x9c\x8däº\x86å\x90\x97ï¼\x9få\x93¥å\x93¥ä½\xa0é\x82£é\x87\x8cé\x99\x8d温äº\x86è®°å¾\x97添衣æ\x9c\x8dï¼\x8cå\x93¥å\x93¥ä½\xa0é\x82£é\x87\x8cä¸\x8bé\x9b¨äº\x86è®°å¾\x97带ä¼\x9eï¼\x8cå\x93¥å\x93¥ä½\xa0å\x9c¨å\x93ªï¼\x9få\x93¥å\x93¥æ\x88\x91请ä½\xa0å\x90\x83é¥\xadï¼\x8cå\x93¥å\x93¥æ\x99\x9aä¸\x8aæ\x9c\x89æ\x97¶é\x97´å\x90\x97ï¼\x9få\x93¥å\x93¥ä¸\xadå\x8d\x88æ\x9c\x89æ\x97¶é\x97´å\x90\x97ï¼\x9få\x93¥å\x93¥è¾\x9bè\x8b¦äº\x86ï¼\x8cå\x93¥å\x93¥ç©¿è¿\x99身ç\x9c\x9få¸\x85ï¼\x8cå\x93¥å\x93¥ä½\xa0ç\x9c\x8bä»\x8aæ\x99\x9aç\x9a\x84æ\x98\x9fæ\x98\x9fï¼\x8cå\x93¥å\x93¥ä½\xa0è¦\x81ç\x9d¡è§\x89äº\x86å\x90\x97ï¼\x9få\x93¥å\x93¥æ\x88\x91è§\x89å¾\x97è¿\x99个ç\x89¹å\x88«é\x80\x82å\x90\x88ä½\xa0å°±ç»\x99ä½\xa0ä¹°äº\x86ä½\xa0å\x88«ä¸\x8dé«\x98 <a'
>>>
这种操作对中文似乎有致命伤啊,所有中文经过这样操作以后,全成乱码了…这可咋整捏?
方案二
下面验证另外一种方法:
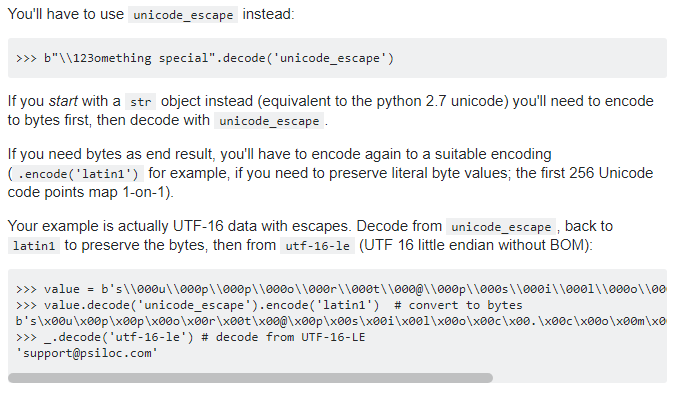
方案三:使用codecs类进行escape_decode



